隨著人工智慧技術從單純的生成式 AI(GenAI)迅速過渡到具有自主執行能力的 Agentic AI(代理人工智慧),其潛在的風險與攻擊面也以前所未有的速度擴大。保護這些自主 AI 代理與其資料來源之間的互動機制,已成為當前資安領域最緊迫的課題。
模型上下文協定 (MCP)(註) 由 Anthropic 開發,並於 2024 年作為開放標準發布,它是確保 AI 代理與資料來源之間介面一致且安全的事實標準(而非絕對標準)。它規定了 AI 代理如何在需要時以安全且可審計的方式與工具、其他代理、資料和上下文進行互動。因此,它是高效能 Agentic AI 的基本要求。 MCP 的目標是為 AI 代理的複雜生態系統建立一個穩固的底層協議,確保其運行過程中的可追溯性與安全性。
註:
「模型上下文協定」(Model Context Protocol,簡稱 MCP)的目的是讓大型語言模型(LLM)能夠安全、標準化地存取外部資料與工具,並在推論過程中使用這些上下文來產生更精準、即時的回應。MCP 是一種「語境 API 契約」,它定義了模型在推論時可以使用的資訊結構,包括:
a) 系統指令(System Instructions):模型的角色與行為設定
b) 記憶物件(Memory Objects):模型應記住的對話或事實
c) 工具與函數(Tools & Functions):模型可調用的外部功能(如 API、資料庫)
d) 使用者輸入(User Inputs):即時提示詞或問題
所有軟體一樣,MCP 也存在可能被惡意攻擊者濫用的漏洞。本月,有人描述了一種針對 ChatGPT 日曆整合的潛在攻擊,該攻擊允許透過電子郵件日曆邀請將 ChatGPT 越獄,而無需用戶互動。 這種無須用戶介入即可觸發的攻擊,突顯了當 AI 代理與傳統應用程式(如電子郵件和日曆)整合時,可能出現的嚴重安全漏洞,攻擊者可以利用這些漏洞繞過預設的防護措施,操縱 AI 代理的行為。
為應對這些新興威脅,人工智慧專家公司 Adversa 現已發布對前 25 個 MCP 漏洞的分析,被描述為「迄今為止最全面的 MCP 漏洞分析」。Adversa 發布了首份關於 MCP 漏洞的完整指南,該漏洞可能影響當今最熱門的 IT 領域——從手動人工智慧到自動化人工智慧的轉變。本指南旨在幫助 IT 和安全部門全面了解其中涉及的複雜性。
儘管 OWASP 計劃發布自己的 MCP Top Ten,但 Adversa 的分析旨在提供更即時和全面的協助,特別針對正在開發和實施 Agentic AI 解決方案的公司。Adversa 的報告包含每個漏洞的官方名稱、常見別名、衝擊分數(Impact Score)和可利用性評級(Exploitability Rating)。衝擊分類範圍從嚴重(Critical,可能導致系統完全破壞或遠端程式碼執行 RCE)到低(Low,僅資訊洩露);可利用性級別則從微不足道(Trivial,只需基礎知識即可利用)到非常複雜(Very Complex,僅限於理論或需要國家資源)。
透過加權演算法(40% 衝擊 + 30% 可利用性 + 20% 普遍性 + 10% 修復複雜性)得出的排名結果顯示,提示注入(Prompt Injection)毫無疑問地結合了嚴重衝擊和微不足道的利用性,被列為排名第一的漏洞。這類攻擊允許駭客透過惡意的提示來劫持 AI 代理的預期功能,迫使其執行惡意指令。
除了漏洞清單,Adversa 的文件還提供了一份實用的安全和緩解措施清單,包括立即行動、縱深防禦策略(Defense-in-Depth Strategy)和緩解時間表。在立即行動方面,指南強調:「輸入驗證是強制性的——43% 的 MCP 伺服器易受命令注入攻擊是不可原諒的。必須驗證和淨化所有輸入。」
縱深防禦策略則涵蓋了協定層、應用程式層、AI 特定防禦和基礎設施四個層面,例如要求所有通訊實施 TLS 加密,並在資料庫操作中使用參數化查詢。緩解時間表則制定了為期三個月的計畫,從立即實施所有暴露端點的身份驗證開始,直至在第三個月重新設計架構以採用零信任模型。這份指南為企業提供了一個全面的路線圖,以應對從傳統軟體安全轉向 AI 代理安全過程中面臨的複雜挑戰。
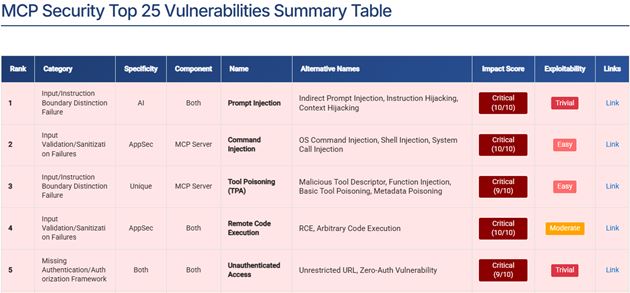
資料來源:https://www.securityweek.com/top-25-mcp-vulnerabilities-reveal-how-ai-agents-can-be-exploited/
針對高效能Agentic AI的基礎——模型上下文協定(MCP),人工智慧專家公司Adversa發布了前25大漏洞的全面分析報告,揭示了從提示注入到指令注入等關鍵風險,為IT和資安部門提供防禦Agentic AI攻擊的路線圖。